Who writes Wikipedia?
It's ten and a half years old, and anyone can contribute, but who does? Who actually writes it? How much do registered users contribute versus anonymous users? How does anonymity correlate with the information-theoretic content of their contributions?
And, also, who un-writes Wikipedia? Who changes a page so unhelpfully that it gets reverted? And how does anonymity factor into that?
There are a lot of ways of adding unhelpful text; for this analysis, we'll only look at the most egregious example, where the page has to be reverted, versus incorporating the edit (with hedges or provisos).
Jimmy Wales, co-founder and promoter of Wikipedia, has asserted that it's a small core of devoted contributors that add the majority of new content; specifically, that over 50% of the edits are done by just 524 users, 0.7% of the user base, and 73.4% of the edits are done by 1400 users, just 2% of the user base. Aaron Swartz did a
study in 2006 that analyzed how much the current version of each page was based on the new content of each page revision, and found that large numbers of anonymous contributors added much more text than a small registered core; specifically that 8 of the top 10 contributors (for a specific page) are unregistered, and that 6 out of the top 10 have made less than 25 edits to the entire site.
Counting sheer number of edits is an imperfect measure of value added to a text, for obvious reasons. Textual size of the diff between a page's new content and the current version of the page, is closer, but still imperfect. Firstly, you'd need to compress the diffs to be accurate in sizing, to take account for pages with long domain-specific vocabulary; ideally, you'd compress literal text differently than text-copying metadata. Secondly, this penalizes anyone who tightens a loosely-written paragraph into a dense sentence. For this analysis, I'm just going to look at information-theoretic gain in each revision, and not focus on impact on the currently final version of the page.
When stated in those terms, compressing the literal text and text-copying metadata differently, LZMA comes to mind. It does Lempel-Zip phrase matching, but has a different statistical model for literals and phrase pointers. Because this analysis doesn't use the impact on the final page, our entropy model for a revisions will be its compressed size when the compression model has been primed on the last 5 revisions. (More formally, the entropy for a revision R_n of a page is bytelength(LZMA(R_n-5 .. R_n)) - bytelength(LZMA(R_n-5 .. R_n-1)).)
(Applying compression to estimate text entropy has been done many times before, often with interesting results. One fascinating poster I saw at the 2003 Data Compression Conference was about comparability of translations: Behr, Fossum, Mitzenmacher, and Xiao, at Harvard, compared different languages' translations of the Bible (one of the most translated books) and several parallel texts from the UN's corpus, finding that even though a language like Chinese was much shorter in bytes than a language like French, they both compressed to similar amounts by PPM (one of the best statistical compressors).)
So.
Who writes Wikipedia?
It's quite complex, and it would be too simplistic to say that registered folks have contributed the majority of the content that has shaped Wikipedia to become what it is, and anonymous folks mostly vandalize. Wikipedia has grown up over the past decade, and its current trajectory mirrors several natural processes for life and growth.
1) The code to churn through Wikipedia.
Wikipedia publishes
data dumps. The XML dump with the complete text of every revision is the pages-meta-history, every revision of every page. It's 40GB of XML compressed, split across 15 files, and 3TB uncompressed. (The compression used, incidentally, is also LZMA, used by the 7zip format.) We'll reduce the problem to something manageable, and only consider pages beginning with the letter M. On
EC2, a 2GHz core-hour is $0.03 and compresses roughly 50k revisions running this code, so if you get an 8-core machine with 7GB of RAM, it'll cost you about twenty dollars for a few days' work.
Each pages-meta-history XML file is composed of {page}
elements, each containing their non-chronological {revision}s. Revisions are highly compressible even with a fast gzip, are relatively short, and are a few thousand in number at most per page. We'll parse the 15 different XML files in parallel and produce work units a line at a time (as JSON objects), splitting into larger work units, and then rely on xargs to use all available cores to consume these work units. It's slightly underengineered, but it's straightforward and gets the job done in an appropriate amount of time.
2) Results.
The data is in a sqlite database, so follow along if you like! I'll give a quick overview of the schema, and then we'll dive in.
When running through the full meta-history, we'll only be looking at revision ids and doing LZMA compression, ripping apart the XML with regexps; for the metadata about revisions and pages and users, we'll be using proper XML parsing on the stub-meta-history. This leads to the tables raw_revisions, pages, and users coming in from parse-stubs.rb, and the table diffs coming in from mh-diff-consumer.rb. The view of the revisions is just the natural join of all these tables, with a few convenience columns thrown in.
So let's start with how much content there is in the revisions of Wikipedia, unreverted (good_contrib) and reverted (bad_contrib).
R1.
select sum(good_contrib), sum(bad_contrib) from revisions;
1028184338, 785454552
There's a lot of user-generated content, and surprisingly, almost as much vandalism as content, 800MB versus 1000MB. Let's break it down by year and anonymity.
R2.
select year, is_registered, sum(good_contrib), sum(bad_contrib) from revisions group by year, is_registered;
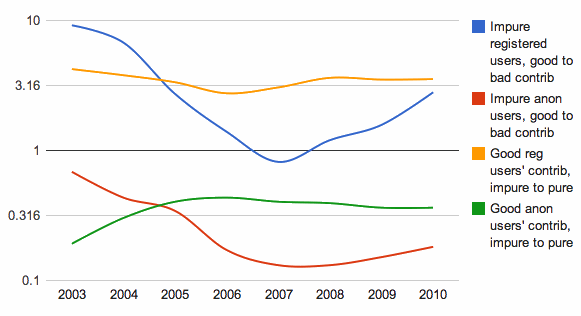
Look at the ratio of good contributions to bad contributions. At the beginning, it's all groundwork that stays. 2005 is the year at which anonymous contributions start to be more bad than good, and 2007 is the year at which registered contributions spike in badness. Let's get a time series of good-to-bad content ratio for registered users, good-to-bad content ratio for anonymous users, registration-to-anonymous ratio for good contributions, and registration-to-anonymous ratio for bad contributions.
R3.

And here, it is apparent. Registered users dipped to contributing as much vandalism as content in 2007, and have taken an upswing to over three times as much good content. Anonymous users dipped to contributing as much vandalism as content in 2005, and through 2010 are contributing roughly twice as much vandalism as content (2011 only goes up to week 11). The total good content has been coming much more from registered users, outpacing anonymous users' contributions 4 to 1, and keeps growing. The total bad content has been coming slightly more from anonymous users than registered users.
So, how should a collaborative community shield against destructive behavior? Imagine a community is trying to collect an "interesting events board". One model is to carefully vet incoming members to ensure they're of the sort to do good work, like a newspaper editorial board. Another model is to allow completely anonymous text, like Craigslist or even 4chan. Another model is to allow differing amounts of anonymity, but to foster a sense of community where people can immediately see other people's contributions and give praise or blame based on the contribution, like an urban cafe's pinboard. Wikipedia, and many social news sites, follow this third way.
It's easy to see that Wikipedia has enough anonymous vandalism as is, and anonymizing more would be unhelpful. But how about the other direction? What would happen if Wikipedia were registration-and-invite-only? What would Wikipedia look like with only contributions from pure contributors, who never made an edit that got reverted?
R4.
create temp table got_reverted (user_id integer primary key);
insert into got_reverted select distinct user_id from revisions where bad_contrib > 0;
select got_reverted.user_id is null as pure, is_registered, sum(good_contrib), sum(bad_contrib) from revisions left join got_reverted using (user_id) group by pure, is_registered;
pure, is_registered, sum(good_contrib), sum(bad_contrib)
0, 0, 59251203, 356581309
0, 1, 623377449, 428873513
1, 0, 154674459, 0
1, 1, 190881227, 0
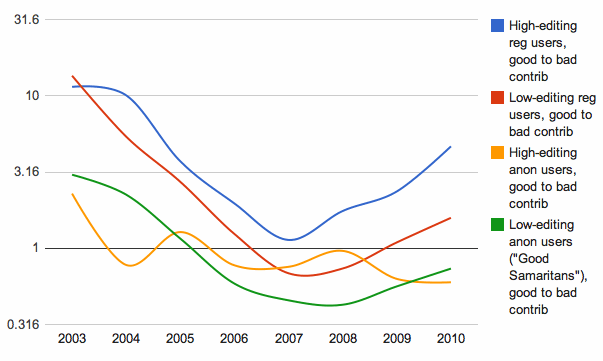
It's optimistic to say Wikipedia would only have a quarter of its current content counting pure users. But it's certainly interesting to see that anonymous vandals mostly vandalize, whereas registered vandals add more value than not. But let's break this down by year, to see the ratio of good-to-bad contributions from impure registered users, the ratio of good-to-bad contributions from impure anonymous users, the ratio of impurity-to-purity in good registered contributions, and the ratio of impurity-to-purity in good anonymous contributions.
R5.
select year, got_reverted.user_id is null as pure, is_registered, sum(good_contrib), sum(bad_contrib) from revisions left join got_reverted using (user_id) group by year, pure, is_registered;
Impure registered users have been adding three times as much content as vandalism. Impure anonymous users have been adding a tenth as much content as vandalism.
Good registered users' contributions are about three times as much from users who have made an unhelpful edit as not. Good anonymous users' contributions are about a third as much from users who have made an unhelpful edit as not.
This is most likely shaping, and shaped by, the Wikipedia policy that if you anonymously make an edit that gets reverted, another unhelpful edit will cause you to be banned. And similarly, sites that allow anonymous content and are not young and small (like Wikipedia in its first dozen months), like Craigslist and social news sites, need to teach newcomers what is valuable and need to ensure that newcomers listen to their advice.
Three folks at Dartmouth measured the good or bad quality of a contribution in the same way as Aaron Swartz, how much of a revision's diff against the previous version of the page appears in the final version, and found that the highest quality contributions come from highly-contributing registered users and single-time anonymous users ("zealots" and "Good Samaritans", in their terminology). Their paper was published in 2007, and a preliminary version was published in 2005; the community has aged significantly since then. Note that 2005 was when anonymous users started vandalizing more than contributing, and 2007 was the year of the minimum content-to-vandalism for registered users.
So let's compare how much good content vs vandalism comes from the population, in total, split by whether they've registered, and then split by the number of edits, whether over 40 or under 4.
R6.
create temp table user_edit_count as select user_id, count(*) as edit_count from revisions group by user_id;
select is_registered, edit_count > 10 as high_edit_count, round(sum(good_contrib * 1.0) / sum(bad_contrib),3) as good_ratio from revisions natural join user_edit_count where edit_count not between 4 and 40 group by is_registered, high_edit_count;
is_registered, high_edit_count, good_ratio
0, 0, 0.583
0, 1, 0.801
1, 0, 1.017
1, 1, 2.134
The more you edit Wikipedia, the more your edits are valuable to Wikipedia. There might indeed be Good Samaritans, but their efforts seem to be outweighed by fly-by vandals. Let's break this apart by year, to see if the numbers might have changed since 5 years ago.
R7.
There it is, the green line of anonymous Good Samaritans, plunging below the 1-good-to-1-bad line in 2006. I'd guess that the study was done on 2005 data, for which that held true; presumably some of the anonymous Good Samaritans created accounts, and lots of the vandalism swamped their good intentions over the second half of the last decade.
What size pages do anonymous and registered users contribute to, both reverted and not? How much do each add per revision, reverted and not?
R8.
create temp table average_page_sizes as select year, avg(page_size) as average_page_size from revisions group by year;
create temp table average_diff_sizes as select year, avg(diff_size) as average_diff_size from revisions group by year;
select revisions.year, is_registered, is_reverted, round(avg(page_size)) as average_page_size, round(avg(page_size) / average_page_size,3) as comparative_page_size, round(avg(diff_size)) as average_diff_size, round(avg(diff_size) / average_diff_size,3) as comparative_page_size from revisions natural join average_page_sizes natural join average_diff_sizes group by revisions.year, is_registered, is_reverted;
So, first we'll look at the yearly average diff sizes, for registered and anonymous users, and for good and bad contrib, and then we'll compare those segmented diff sizes against the year's average diff size. Next, the same for page sizes that registered/anonymous users gave good and bad contributions to.
And pages:
Registered contributors' contributions get reverted more on larger pages, whereas anonymous contributors' contributions get reverted more on smaller pages. While the average page size is going up, the average size where one can make a productive contribution is rising more slowly. Anonymous users who make small contributions fare better on larger pages than registered users. Interestingly, registered users' bad contributions are significantly greater, information-theoretically, than registered users' good contributions, and anonymous users' good contributions are slightly greater than anonymous users' bad contributions. These numbers have stayed relatively constant over time, suggesting it might be possible to classify revisions as vandalism partly by the information-theoretic content.
From R2, we've seen that registered users add more, in total, than anonymous users. What's the dropoff?
R9.
create temp table user_edit_amounts as select user_id, sum(good_contrib) as goods, sum(bad_contrib) as bads, is_registered from revisions group by user_id;
select goods from user_edit_amounts where is_registered order by goods desc limit 1000;
select goods from user_edit_amounts where not is_registered order by goods desc limit 1000;
The top registered editors give much more good content than the top anonymous editors. Who are these fantastically productive registered users? Those people have contributed enormous amounts, they must work like machines!
R10.
select name, goods from user_edit_amounts natural join users order by goods desc limit 50;
SmackBot, 9227561 *
RjwilmsiBot, 6828002 *
Dr. Blofeld, 3936971
Ram-Man, 3050752
Kotbot, 2885893 *
Leszek Jańczuk, 2496383
Yobot, 2269891 *
Rich Farmbrough, 2152852
AlbertHerring, 2011080
Ser Amantio di Nicolao, 2011080
Polbot, 1727872 *
Cydebot, 1689522 *
CapitalBot, 1643092 *
The Anomebot2, 1607194 *
Lightbot, 1574000 *
TUF-KAT, 1391214
Alansohn, 1266745
Starzynka, 1256326
Bearcat, 1194658 *
Rjwilmsi, 1186757
Rambot, 1133351 *
RussBot, 1124530 *
Geo Swan, 1106468
DumZiBoT, 981678 *
ProteinBoxBot, 960781 *
Ganeshbot, 960205 *
WhisperToMe, 939078
Darius Dhlomo, 920829
Eubot, 920828 *
Viridiscalculus, 911794
D6, 861183 *
Full-date unlinking bot, 851573 *
Arcadian, 829771
BOTijo, 827633 *
Orderinchaos, 823965
Lugnuts, 818752
Plasticspork, 809442 *
Plastikspork, 779035
Carlossuarez46, 773060
Geschichte, 752836
Imzadi1979, 735127
Wetman, 726056
Luckas-bot, 722364 *
PageantUpdater, 713171 *
Attilios, 700275
Charles Matthews, 664671
Droll, 645061
Thijs!bot, 636961 *
CJCurrie, 634663
Colonies Chris, 608999
Indeed they are machines. About half of the top 50 contributors are bots.
Two interesting observations:
In ten short years, looking at the information-theoretic contributions of users, it's possible to see Wikipedia grow up and become an enormous ecosystem of a wide variety of contributors. But this analysis is just scratching the surface: take the code on Github, the lightweight dataset on Infochimps, and let me know what you come up with!